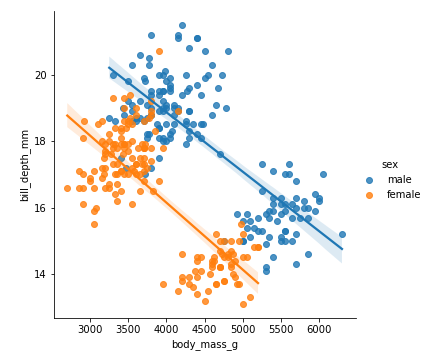
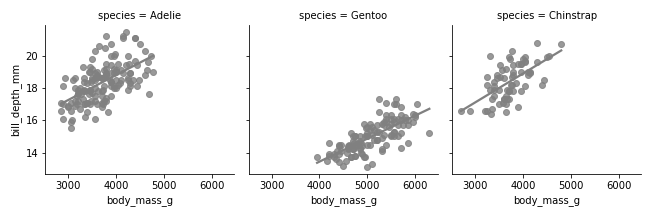
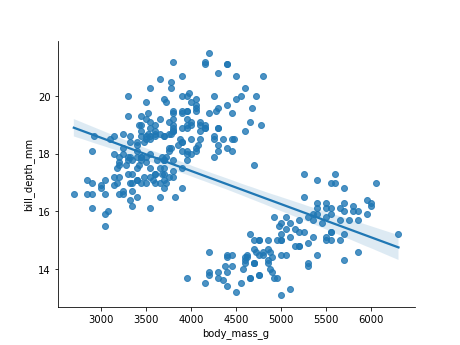
Section Simpson paradox
parent
49fe03fa
No related branches found
No related tags found
Showing
- notebooks/machine-learning/1.machine-learning.ipynb 25 additions, 19 deletionsnotebooks/machine-learning/1.machine-learning.ipynb
- notebooks/machine-learning/images/penguins-by-sex-simpson.png 0 additions, 0 deletions...books/machine-learning/images/penguins-by-sex-simpson.png
- notebooks/machine-learning/images/penguins-by-specy-simpson.png 0 additions, 0 deletions...oks/machine-learning/images/penguins-by-specy-simpson.png
- notebooks/machine-learning/images/penguins-simpson.png 0 additions, 0 deletionsnotebooks/machine-learning/images/penguins-simpson.png
{kind=link}
35.8 KiB
{kind=link}
22.8 KiB
{kind=link}
27.9 KiB